

Live video streaming technology is an integral part of the PPIO platform. While you get the end result, the technology behind it is complicated. We break it down and share the secrets of video streaming so you get the full picture.
We’re focused on creating cutting edge technology for developers to platforms and applications focused on media streaming. In our epic two-part series on The Secrets of PPIO’s Data Delivery Technology (Part 1 and Part 2), we shared why we’re choosing to stream media and explained diverse topics such as PCDN, fragmentation, the role of nodes, download logic, buffer management, and more.
To recap our approach to development and commercialization, we recommend you read How We’re Structuring Our Technology For Commercialization. Of course, if you don’t have time, the image below will show exactly where streaming sits on the PaaS layer and where that fits in the overall structure of PPIO.

Types of Live Streaming
Live streaming can be divided into two categories:
Mass Streaming: Typically watched by many people, but with little interaction between the live streamer and the viewer. Given the number of people watching, there is not much room for interaction between the viewer and the streamer. This type of streaming is common, examples being live TV broadcasts, live sports, or streams of big events like concerts or parades. In other words, it is all about scale, and there is a low demand for delay and simultaneity.
Interactive Low-Latency Streaming: Does not require a large number of viewers, but will involve real-time interaction between the streamer and the audience. Typically the interaction between both will determine the type of content and the quality. For this type of steaming, low latency and synchronization are very important.

For both types of streaming, it is important to clarify two important concepts:
Delay: When an action performed on screen is transmitted after it occurs. For example, in football matches, if what occurs in real-time is received by the audience 30 seconds later, then the delay is 30 seconds.
Simultaneity: When an action performed on screen is transmitted at the same time that it occurs. A lot of advanced interactions, such as live answering of questions, involve simultaneity.
We initially thought that we could simultaneously account for both scenarios via a set of technical solutions, however, we found this difficult because of a theoretical problem: the invisible tree principle of P2P transmission.
The principle of the invisible tree is that even though P2P transmissions are designed as a mesh model, it will naturally form a hierarchical tree-like structure when it is actually transmitted.

On the micro-level, each data fragment (i.e. each Piece) is distributed from the source to the Peer located at the first level. From there it then reaches the Peer at the second level, and then to the Peer at the third level, until all Pieces are distributed to all Peers. Every Piece has to go through this process, though some Pieces may have no distribution path.
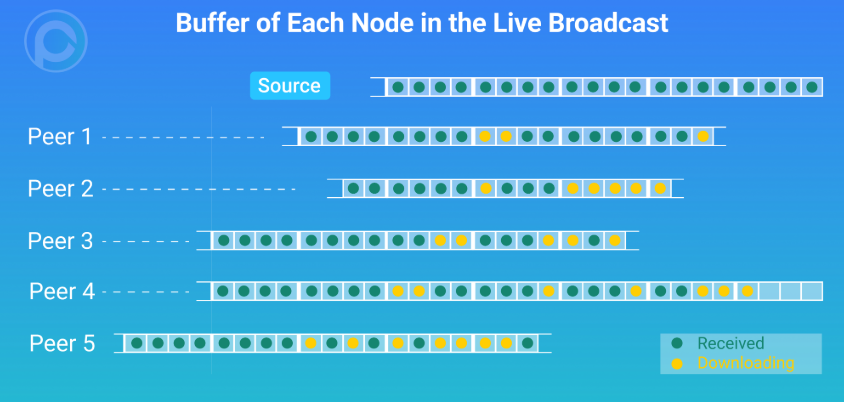
Buffering, which is a necessity of live streaming, is always moving forward, which makes the Buffer location of each Peer different. Some nodes may be closer to the newly generated Piece, while those near the Source are closer to the Buffer location; they get the latest data first and then distribute it to other nodes. This then gradually differentiates into a series of Peers which are distanced from the Source node and form a tree-like structure. It is not quite a tree in the strictest sense, hence the name invisible tree.
The dense lines in the transmission line are like the trunk, whereas the less dense lines in the transmission line are regarded as virtual trunks.
In theory, large scale and low latency are inherently contradictory. As a result, we need to develop two different strategies in order to account for scenarios that operate on a large scale or require low latency. In this article, we will explain how our network works for large-scale live video streaming.
Live Sharding
In our viral article on Why Are We Streaming Media? we explained how our data fragmentation technology works and how it powers P2P transmissions.
From a perspective of slicing, live broadcasts are more complicated than video-on-demand. Because the live broadcast has neither the starting point nor the ending point, each user starts watching the live broadcast while downloading the intermediate data. And all users’ data should be fragmented according to the same rules; so not only to slice but also to synchronize. In addition, the general live broadcast also has a playback function.
HTTP Segmented Streaming Live
HLS is used as an example here, though DASH and other methods are also similar.
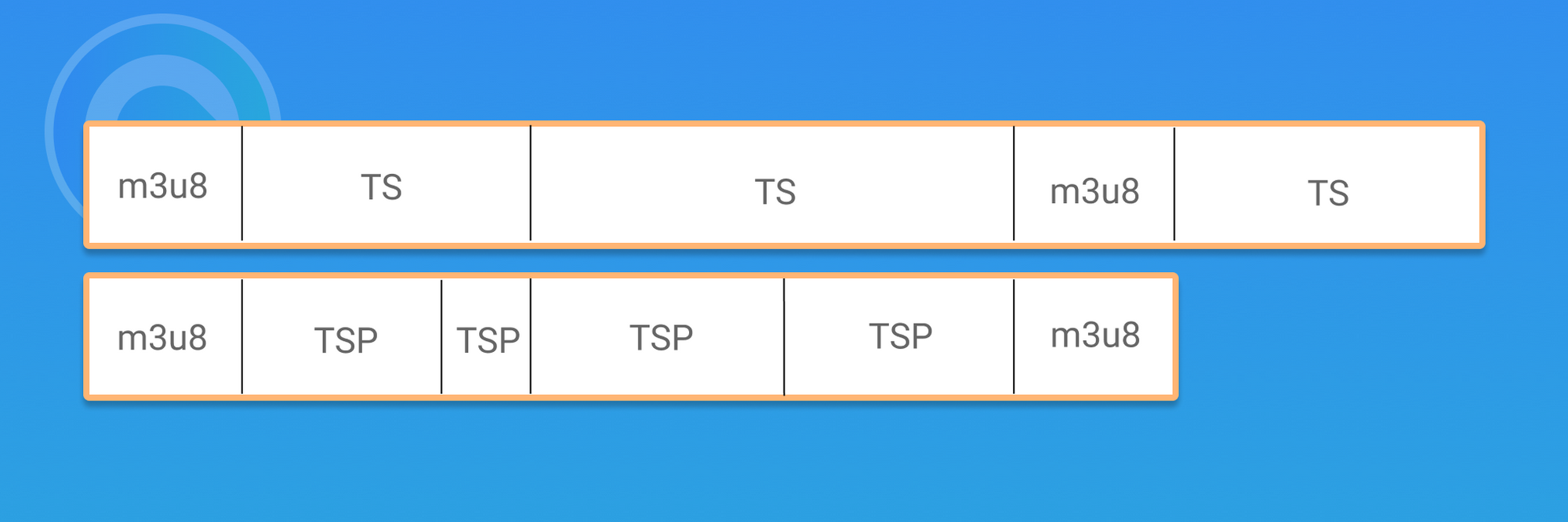
The slice method of HLS live broadcast and the HLS on-demand are the same when assuming that the m3u8 file conducts the live broadcast and plays TS1, TS2, TS3, TS4, TS5. According to the setting of the standard latency, the live broadcast will start from a certain TS, for example, when playing from TS1, the live delay is the longest, so it is more likely to get data from the P2P network, thus the P2P bandwidth ratio will be higher. However, if it is playing from TS5, the live delay is the shortest, so the chance of getting data from the P2P network will be less and the P2P bandwidth ratio will be lower. If we play from TS3, then there will be a compromise.
HTTP Continuous Streaming Live
HTTP Continuous Streaming Live means there is no end to streaming. HTTP+FLV is used as an example here.

The VS of a FLV live stream is not necessarily equal in length. The VS starts with the keyframe as the boundary and slices the time with a minimum time unit. The slice algorithm ensures that the data of each frame in each VS is complete and contains a keyframe.
Assuming that the current live broadcast plays VS1, VS2, VS3, VS4, VS5, according to the setting of the standard live delay, if it is playing from VS1, the live delay is the longest, and may have more opportunities to get data from the P2P network, therefore the P2P bandwidth ratio is the highest. On the contrary, if it is playing from VS5, the live delay is the shortest, the chances of getting data from P2P will be less and the P2P bandwidth ratio will be the lowest. Therefore, playing from the VS3 results in a somewhat compromised formula.
It is worth noting that apart from two streaming media modes mentioned above, PPIO plans to support other media formats and protocols step by step. Finally, Fragmentation only establishes the order of P2SP downloads; there are actually many large and small differences in live streaming systems.
Live Channel and Unique Tags
On the PPIO system, file downloads and on-demand streaming are the only unit of the file as a resource, because as long as the file is determined, its RID (unique ID) can be calculated. However, live streaming is different. The data involved in live streaming is seemingly endless, with no definite method to calculate the total data used. To account for this, we can artificially mark a live signal source as a channel, and then give it a unique ID. Each module then stipulates and uses this unique ID to properly transfer and retrieve data.
Buffer Management
Buffer management for file downloads and on-demand streaming are also different. Buffering for on-demand streaming is fixed, while live buffering is always moving forward.
When designing PPIO, we divide buffering into multiple intervals according to the video playback position when streaming media. The closer to the playback position, the higher the download priority. These four intervals are: Interval Before Playback, Urgent Interval, Normal Download Interval, and Long-term Interval. For more information on these four intervals, see Why Are We Streaming Media? Part 2.

Live buffering also has the same four states, however, there are certain key differences in terms of buffering:
- Urgent intervals will be saved for a long time so that it can be uploaded to others; whereas live intervals will be deleted after a period of time because live historical data will be meaningless after a period of time as other Peers will no longer have a need to request it.
- The long-term range of on-demand streaming may be long and far; whereas live streaming basically has no long-term range, because new data has not yet been generated from the Source node.
- Play-on-demand will eventually end; whereas live-play may never end.
Live data caching only needs to cache the data played. Because of this, live data caching does not need to be written to the hard disk; it only needs to be stored in memory. The on-demand cache is placed in the device’s storage.
In addition, if during a live stream you find that your playing progress is far behind other Peers, you can disconnect your connection, perform a relocation, then find a new and more suitable playback location.
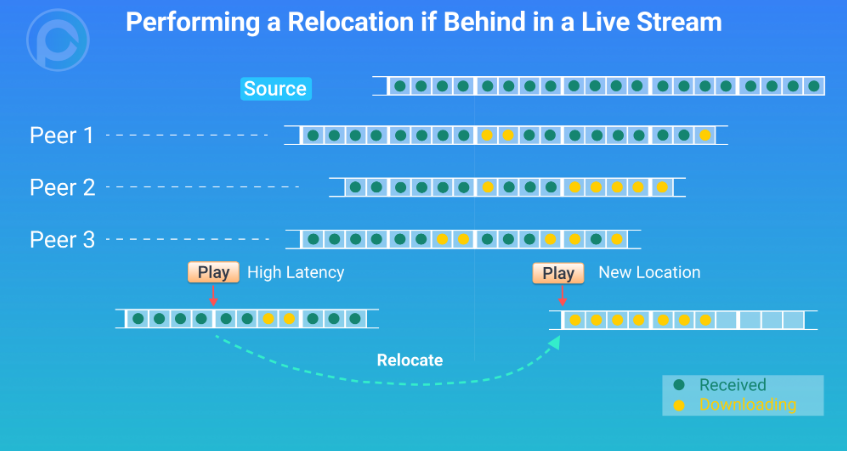
After you relocate, some data will be skipped, however, the player is able to keep up with the progress of the overall P2P network.
Subscription Agreement
For network downloads and on-demand streaming, we designed a Request-Response protocol. The implementation mechanism assumes that the User makes decisions about the data to be requested by choosing the playback position. The User knows what needs to be buffered for playback and what doesn’t need based on what the User has already watched. From a technical perspective, the User requests a map from other connected Peers, which marks which Pieces they have and which Pieces they don’t have. We call this map Bitmap. With the Bitmap for these Peers, the resources of each Peer are shown. The User will go to different Peers to request different Pieces according to the pre-designed algorithm, and the Peers will return the data after receiving the data request. We call this the pull mode.

For live streams, we adjust the strategy of pull mode as it is not enough to match the pace of the stream. Instead, we focus on getting the latest Bitmap. Each Peer’s Bitmap changes quickly in a live stream, with situations where the Bitmap can charge every second. As mentioned earlier, as every Peer is helping to buffer the latest Piece, so the pace of the buffering must keep up with the demand.
As a result of the above, we designed a new method called subscription mode. For the User, each Peer connected to it should be evaluated in terms of resources, download speed, and so on. Once identified as a high-quality Peer, a subscription application is sent to it, and as soon as it receives new data, it is immediately forwarded to the User. This high-quality Peer can agree or reject when it receives a subscription request because it also needs to evaluate its own service capabilities. When the User finds that subscriptions are no longer needed, it can issue a cancellation to the Peer.

Because of the uncertainties of network transmission, subscription mode can not guarantee that all Pieces can be pushed on time, so the actual implementation is a combination of subscription mode and pull modes. When a Piece is not received on time, it is retrieved in pull mode, and if the Piece is located in an emergency area of the buffer management, multiple redundant requests may be initiated.
PPIO has is being built with a commercial landing in mind, hoping to use technology for business and to benefit the consumer. Streaming media has always been part of our strategy and we place great importance on it. In this post, we focused on the design of the PPIO network for large-scale live streaming, how to establish the order of P2SP download through fragmentation, and how buffer management works. We also discussed the differences between live streaming and on-demand downloads, and how to use the combination of subscription mode and pull mode to better support large-scale live streaming scenarios.
In our next article, we will delve deep and discuss the subscription model and the importance of low-latency interactive live streaming which is becoming increasingly popular. Stayed tuned. If you can’t wait, check the join the PPIO community on Discord or follow us on Twitter for more PPIO goodness.